The Scaling Journey of a Cloud Native Application
Introduction
You are the CTO at a startup that is launching its service in a promising new industry. After several months of development and testing, you are running a reliable and performant application on the AWS cloud. One day, your system starts experiencing an unusual number of requests. You indentify these as new users signing up and trying out your innovative service. The traffic remains consistent and is expected to increase as more users join; your startup is a success and is exploiting mass market! However, while the business team is celebrating the record numbers, your monitoring system reports degrading performance metrics and an increase in the number of errors. In addition, some users are starting to complain about your service being slow or even unresponsive. You realize that your current architecture is not capable of handling the new volume of users. As an experienced AWS architect, you set out to evolve your cloud architecture and allow your company to reach its full market potential!
Stage 1: Early Days
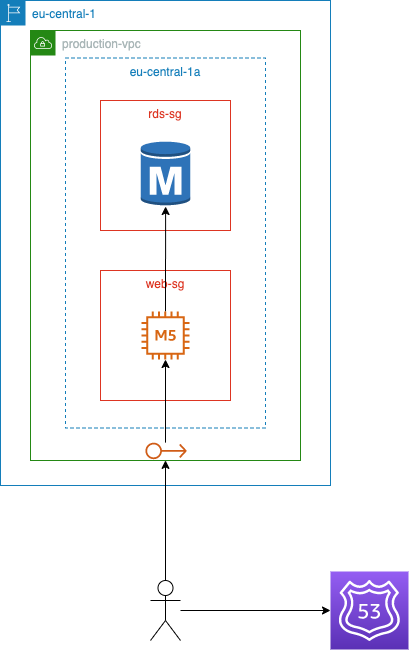
You initially launched the service in a traditional three-tier architecture where the web application runs on an EC2 instance backed by a relational database. This served your group of early adopters well while keeping complexity and costs low. Whenever you hit a new resource bottleneck you just had to resize the underlying instances, also known as vertical scaling. For better or worse, your system is increasingly handling a larger volume of new users and you realize that at this rate you will reach its limits in a few weeks. Moreover, your company can no longer tolerate downtime because of infrastructure failures, migrations, or new releases. You need to maintain service availability for your customers.
Stage 2: Better Safe than Sorry
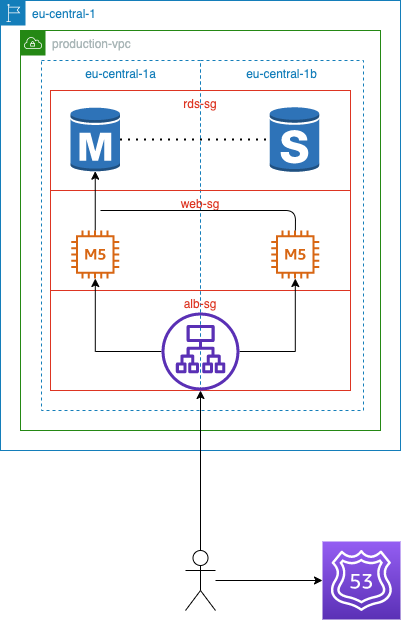
Your first attempt to increase capacity is to add another EC2 instance and distribute the incoming traffic, also known as horizontal scaling. The load will be distributed evenly across web servers by an application load balancer. You immediately notice the improvements in performance and stability. You also address the issue of high availability by distributing the web servers over two availability zones and deploying a standby RDS instance. A couple of months later you start receiving new alerts from your system. It looks like new users are having trouble signing up and are unable to use your service.
Stage 3: The Bookworm
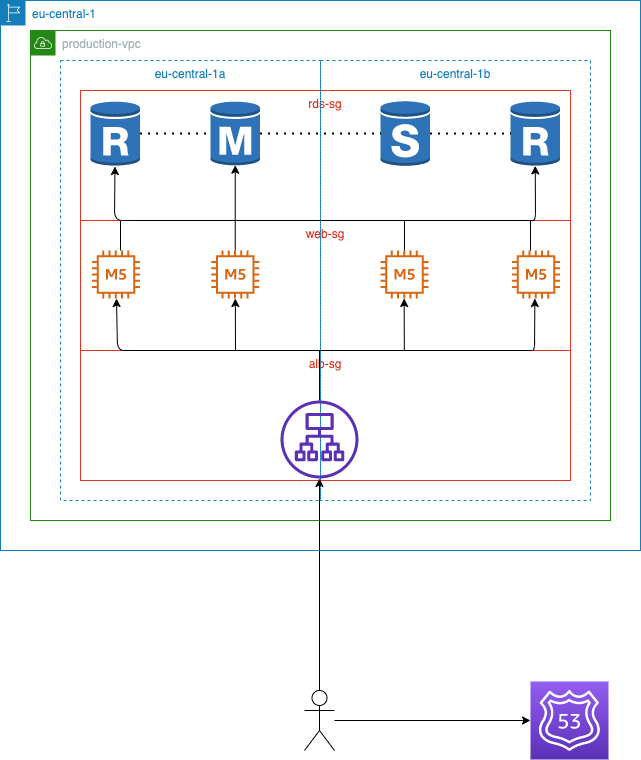
Once again, the first thing you do is to add another EC2 instance in each zone to increase capacity. The web servers revert to normal operation and the number of sign-ups resumes increasing. A couple of hours later though, your service is unresponsive once more. This time the web servers have enough spare capacity and do not seem to be the problem. Eventually, you notice that the master RDS instance is running at peak capacity which coincides with connection errors in the web server logs. Knowing that most of your database queries are read-only, you decide to spin up read replicas alongside your main RDS instances. Next, you configure the web application to direct all read-only queries to the replicas. The service is now handling a record number of users without breaking a sweat! Following the startup’s huge success, the stakeholders decide on expanding the service to new regions with a big marketing budget. This time you want the system to be ready when the service goes global.
Stage 4: The Great Expansion
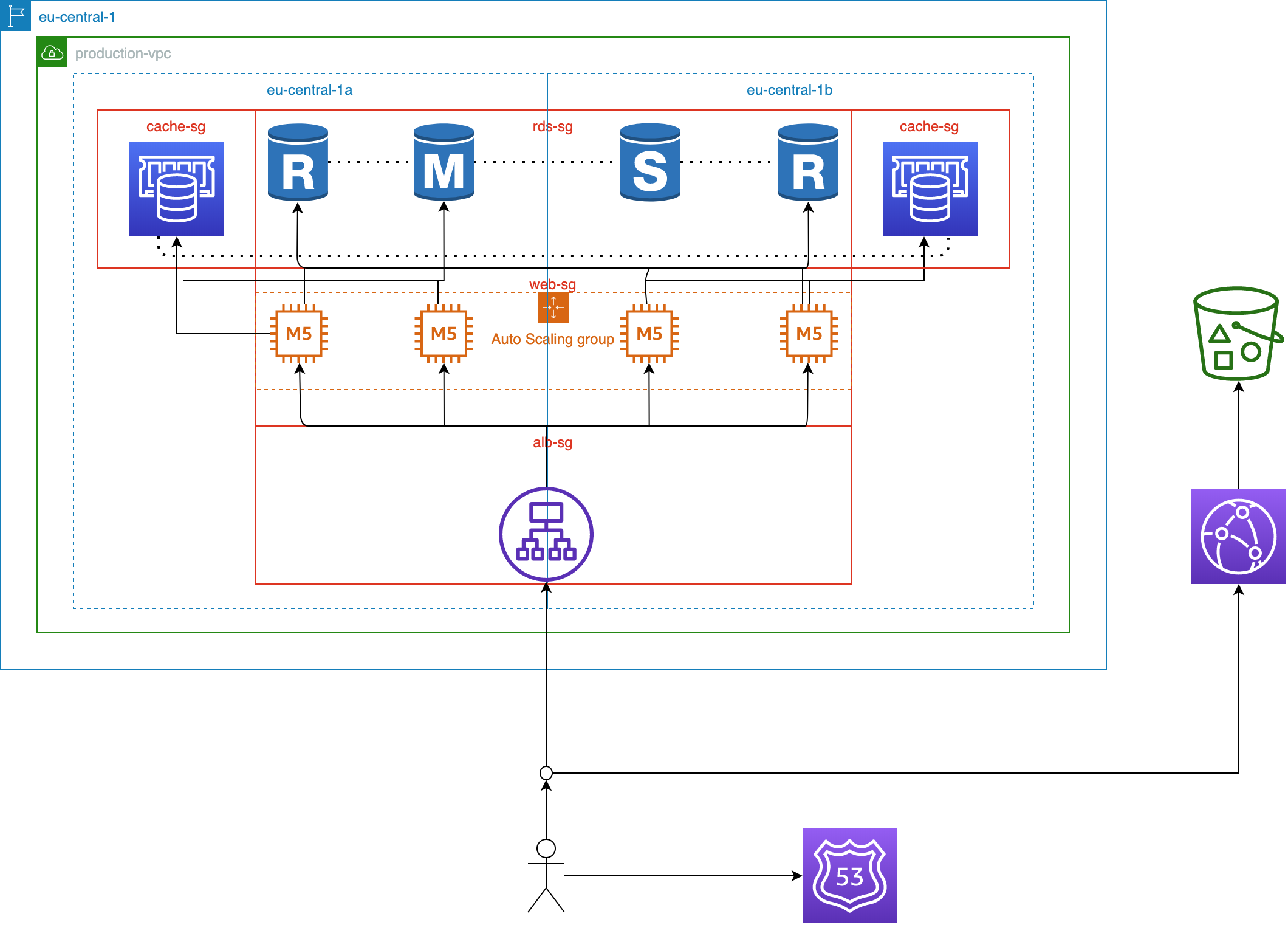
In order to keep up with the global demand, you decide to rearchitect your service into a modern single page application. This frees the web servers from serving static content and the frontend team can now focus on building a fast and rich user experience decoupled from the backend. After moving your frontend assets to S3, you can now serve your website through the CloudFront CDN network and guarantee a high-quality experience for users all around the world. Next, you move on to your application backend. You start by adding an ElastiCache cluster to serve the most frequently accessed content from your database. Then, you decide to place your EC2 instances in an auto-scaling group to automatically provide additional capacity when needed. Luckily, your efforts are starting to bear fruit! In the following quarter, users are showing up from new countries and continents. Traffic is growing at a breakneck pace and your system is sufficiently handling all requests. The sales and marketing team are making the best use of their budget! During your great expansion, the development team is constantly adding exciting features and enhancements to the service. Sooner or later you hit an unexpected milestone: The front page of the internet! A wave of curious users coming in from viral social media posts are starting to push your system to its limits. This is it, your service either stands up to the fickle demands of the netiznes or is left behind serving a loyal user base. You are going to have to optimize your architecture from top to bottom and squeeze every bit of performance and efficiency out of the AWS cloud!
Stage 5: The Front Page of the Internet
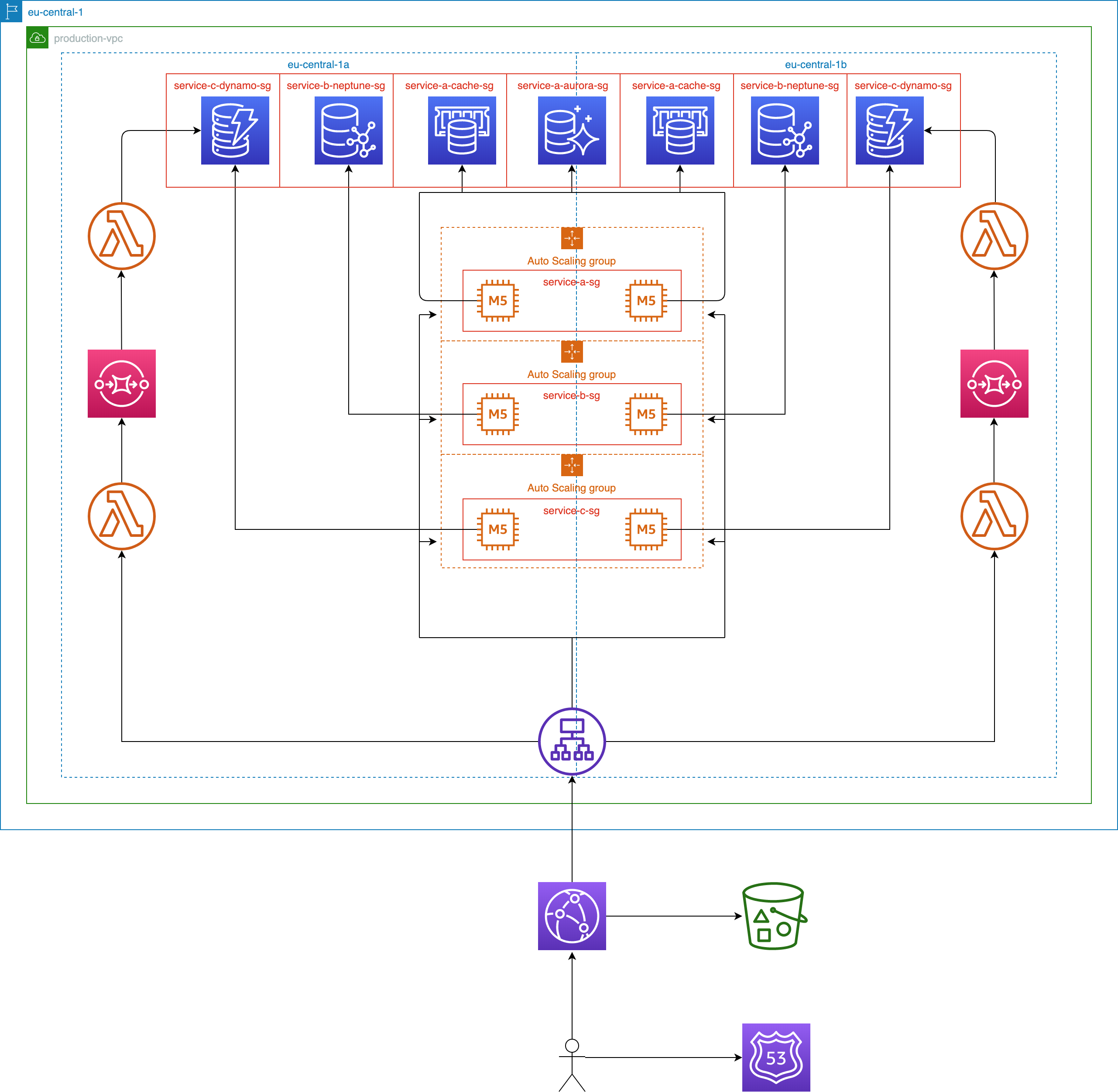
You and your team embark on a major architectural reform to fully embrace the elasticity and high availability of the AWS cloud. So far, your service has been developed as a multi-module monolithic application. This simplified the development process and made your application easily scalable by adding more web servers. However, it has reached a point where it is responsible for a large number of features whereupon scaling it as a monolithic bloc is no longer economical. Furthermore, your development team has grown mature enough to split up and handle dedicated feature sets within groups. You decide that it is time to make the leap and refactor the web application into several small and independent services, also known as the microservices pattern. Teams can now optimize each service according to its needs and allow it to scale independently based on its own demand. They start by choosing a specialized database that is best optimized for executing the business queries. Then, they identify simple operations that are being heavily executed and migrate them to Lambda functions. This guarantees their automatic availability and scalability while running on AWS’s own managed infrastructure. Finally, you further optimize your end user latency by directing requests for dynamic content through CloudFront. Thanks to the team effort, the different parts of your system automatically adapt and efficiently handle the new spike in demand.
Day One Checklist
Since the first day of launching your service, you made sure to follow these operational best practices:
- Centralize logging and monitoring using CloudWatch.
- Deploy application configuration and code changes using a CI/CD pipeline such as CodePipeline.
- Provision infrastructure as code using CloudFormation.
- Automate your EC2 fleet management using System Manager.
- Assess the state of your environments using TrustedAdvisor, Inspector, and GuardDuty.
- Monitor your AWS bill using Cost Explorer and Budgets.
Congratulations
You were able to successfully keep your service up and running in the face of your startup’s rapid expansion while efficiently using the power of the AWS cloud!